Étude de cas : 61 % de mention IA, face à un leader à 89 %
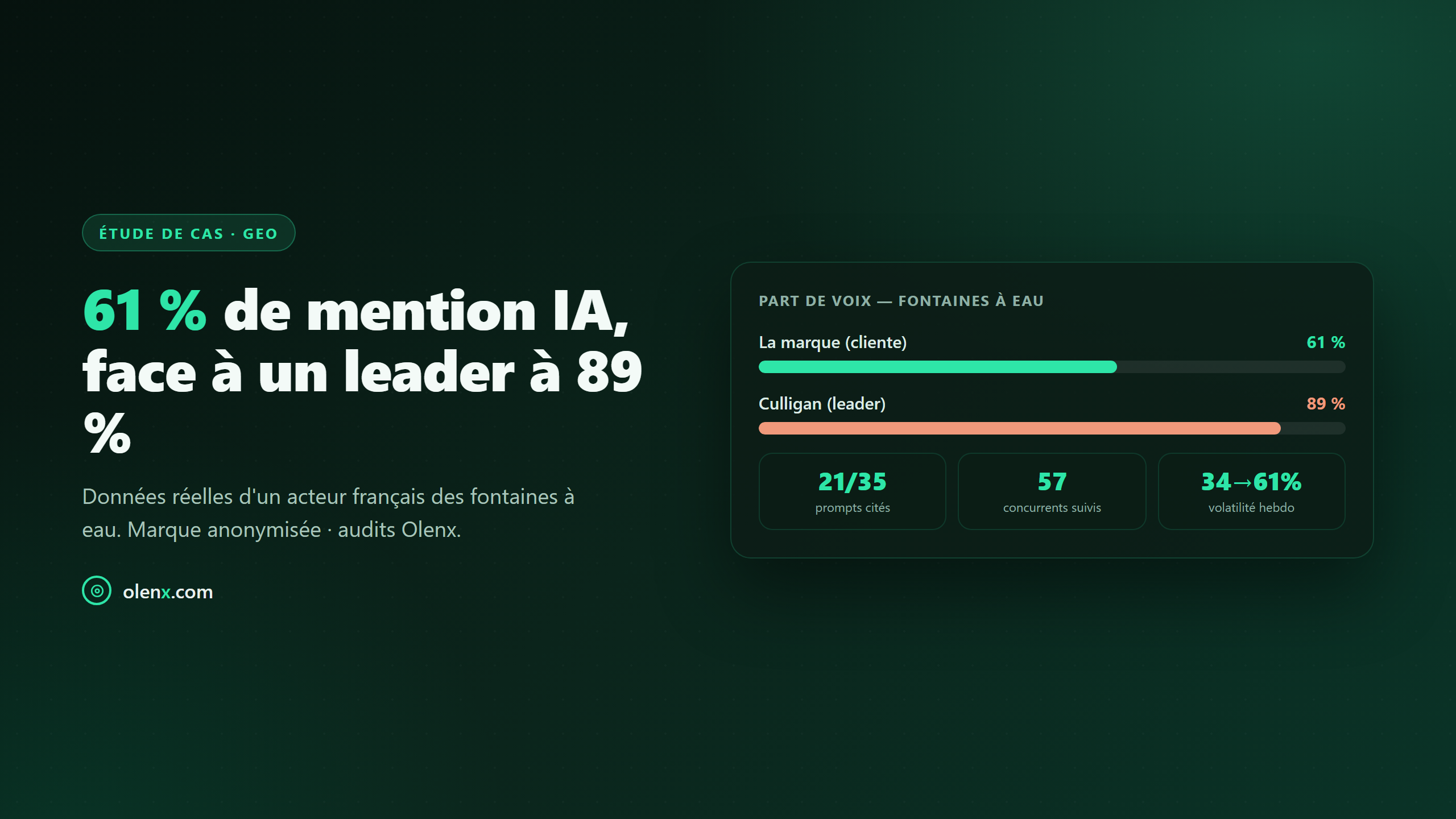
En bref — Un acteur français des fontaines à eau est cité dans 61 % des requêtes testées (21 prompts sur 35) sur ChatGPT — un bon score, mais il reste derrière le leader du secteur, Culligan, qui occupe 89 % de la part de voix. Ses audits hebdomadaires révèlent trois leçons valables pour n'importe quelle marque. Données réelles, mesurées sur la plateforme Olenx, marque anonymisée.
Le contexte
La marque suivie ici est un fournisseur français de fontaines à eau pour les entreprises — un marché B2B concurrentiel, où la recommandation compte autant que le référencement. Quand un office manager demande à une IA « quelle solution de fontaine à eau pour mes bureaux ? », la réponse cite une poignée d'acteurs. Y figurer, ou non, décide d'une partie du pipeline commercial.
Sur ce marché, l'outil suit 57 concurrents. Avant toute optimisation, la première étape a été de mesurer si la marque était déjà citée — et à quelle hauteur.
Les chiffres réels
taux de mention de la marque (21 prompts cités sur 35)
part de voix du leader, Culligan, sur les mêmes requêtes
concurrents suivis sur le marché
61 % de mention, c'est loin d'être négligeable : la marque est bien installée dans les réponses. Mais la lecture comparative change tout — face à un leader à 89 %, il reste un vrai différentiel de visibilité à combler. C'est précisément ce que révèle la part de voix : être cité ne suffit pas, encore faut-il peser face aux concurrents.
Leçon n°1 — la citation IA est volatile
Le suivi hebdomadaire a capté ce qu'un scan ponctuel n'aurait jamais vu. Sur une semaine, le taux de mention est descendu nettement, avant de remonter :
le taux de mention relevé une semaine (19 mai) — avec 10 citations gagnées mais 4 perdues sur la période. Le score est ensuite remonté à 61 %.
Cette volatilité est la règle, pas l'exception : les réponses des IA varient d'une semaine à l'autre. Sans suivi régulier du taux de mention, on prend une photo à un instant T qui peut être trompeuse — dans un sens comme dans l'autre.
Leçon n°2 — un seul moteur ne donne qu'une vision partielle
Soyons transparents sur une limite de ce cas : la couverture portait sur 1 moteur sur 4 (ChatGPT), faute d'avoir branché toutes les clés API. Or une même marque peut être forte sur un moteur et absente d'un autre.
C'est exactement pourquoi un suivi multi-moteurs est indispensable : se fier à un seul modèle, c'est piloter avec un œil fermé.
Leçon n°3 — le vrai combat est concurrentiel
Le chiffre le plus instructif n'est pas le 61 % de la marque, mais le 89 % de Culligan. Sur ce marché, un acteur historique domine les réponses IA. La marque suivie n'a pas un problème d'absence — elle a un problème de part de voix face à un leader très cité.
Identifier qui vous prend des citations, sur quelles requêtes, et pourquoi, transforme une donnée brute en plan d'action. C'est l'objet du suivi des concurrents dans les IA.
Ce que votre marque doit en retenir
Mesurez votre point de départ. Un chiffre réel (taux de mention, prompts cités/total) vaut mieux que des hypothèses.
Couvrez les quatre moteurs. ChatGPT, Claude, Perplexity, Gemini — un seul ne révèle qu'une face du résultat.
Suivez la volatilité. Mesurez chaque semaine : un bon score ponctuel peut masquer une tendance.
Benchmarkez vos concurrents. Votre part de voix face au leader dit où se trouve le vrai potentiel.
Quel est VOTRE taux de mention ?
Audit gratuit sur ChatGPT, Claude, Perplexity et Gemini — avec votre part de voix face aux concurrents.
Lancer mon audit gratuit →FAQ
Les chiffres de cette étude sont-ils réels ?
Oui. Ils proviennent d'audits réellement effectués sur la plateforme Olenx (mai–juin 2026) pour un client réel, dont le nom est anonymisé. Le taux de mention (61 %) correspond à 21 prompts cités sur 35 testés, mesurés sur ChatGPT.
Pourquoi un seul moteur a-t-il été mesuré ?
Par configuration : toutes les clés API n'étaient pas branchées au moment de l'audit. C'est une limite assumée — un suivi complet couvre les quatre moteurs, car les écarts entre eux sont souvent importants.
61 %, c'est bon ou pas ?
En valeur absolue, c'est un bon score. Mais face à un leader à 89 % de part de voix, il reste un différentiel à combler. La citation seule ne suffit pas : c'est le poids relatif face aux concurrents qui compte.
Comment obtenir le même type d'analyse pour ma marque ?
Un audit Olenx mesure votre taux de mention, votre part de voix et vos concurrents sur les quatre moteurs, puis suit l'évolution dans le temps.
Méthodologie
- Données propriétaires : audits réalisés sur la plateforme Olenx, mai–juin 2026, pour un client réel du secteur des fontaines à eau (marque anonymisée).
- Taux de mention = nombre de prompts où la marque est citée / nombre de prompts testés (21/35). Mesures principalement sur ChatGPT ; part de voix calculée face à 57 concurrents suivis.
Prêt à optimiser votre visibilité IA ?
Recevez votre audit de visibilité IA gratuit et découvrez votre taux de mention.
Voir si ChatGPT me citeL'équipe Olenx
Ingénieurs en Generative Engine Optimization. Olenx mesure la visibilité des marques sur ChatGPT, Claude, Perplexity et Gemini.
Articles liés
Building Brand Authority That LLMs Cite
Learn how to build the off-site brand authority that makes LLMs like ChatGPT, Claude, and Perplexity cite your brand — from third-party coverage to consistent entity signals.
How to Track Your Brand's AI Visibility
Learn how to track your brand's AI visibility across ChatGPT, Perplexity, and Google AI Overviews—measuring mention rate, share of voice, citations, and automating prompt monitoring.
Structured Data for AI Citations: A Practical Schema.org Guide
Schema markup for AI search is no longer optional. Learn which Schema.org types—Organization, Product, FAQ, Article—drive AI citations in ChatGPT, Perplexity, and Google AI Overviews, plus how to implement them right.